- Written by: Hummaid Naseer
- September 4, 2025
- Categories: AI Tools & Frameworks
Artificial Intelligence (AI) and Machine Learning (ML) have become the backbone of modern technology, powering everything from recommendation engines and autonomous vehicles to advanced medical diagnostics. At the heart of this revolution lies Python, the programming language that has emerged as the industry’s undisputed leader for AI and ML development. Its simplicity, readability, and extensive ecosystem of libraries make it the go-to choice for researchers, data scientists, and engineers alike. Unlike other languages, Python strikes the perfect balance between rapid prototyping and production-grade scalability, allowing teams to move from idea to deployment with unmatched efficiency. With a vibrant community, powerful frameworks like TensorFlow, PyTorch, and Scikit-learn, and seamless integration with data processing tools, Python continues to dominate the AI and ML landscape, and its role is only growing stronger as technology advances.
NumPy and Pandas: The Backbone of Data Preparation
In AI and Machine Learning, data is everything. But raw datasets are rarely ready for training; they often contain missing values, duplicates, inconsistent formats, or irrelevant information. That’s why data preparation is considered one of the most time-consuming yet essential steps in any ML pipeline. Two libraries have become indispensable for this process: NumPy and Pandas.
NumPy: The Powerhouse for Numerical Computation
NumPy (Numerical Python) is the foundation of scientific computing in Python. At its core lies the ndarray (n-dimensional array), a fast and memory-efficient structure that enables vectorised operations, meaning computations are applied to entire arrays at once, rather than looping through elements.
Key strengths of NumPy in data preparation:
Efficient storage and performance: Handles large numerical datasets much faster than native Python lists.
Mathematical operations: Provides functions for linear algebra, Fourier transforms, and statistical analysis.
Integration: Serves as the underlying engine for many ML and scientific libraries (e.g., TensorFlow, SciPy, Scikit-learn).
Example use case: Standardising datasets before training a model (e.g., normalising values, reshaping arrays for neural networks).
Pandas: Intuitive Data Manipulation
If NumPy is the raw computation engine, Pandas is the user-friendly interface for structured data. Built on top of NumPy, it introduces DataFrame and Series objects that make handling tabular and time-series data simple and intuitive.
Key strengths of Pandas in data preparation:
Data cleaning: Handle missing values, duplicates, and incorrect formats with ease.
Data transformation: Merge, join, group, and pivot large datasets with minimal code.
Data exploration: Quick statistical summaries, filtering, and indexing help uncover patterns.
Compatibility: Easily imports and exports data from CSV, Excel, SQL, and JSON formats.
Example use case: Cleaning a customer dataset by filling missing age values, converting date formats, and grouping purchases by customer ID before feeding data into a churn prediction model.
Why They Work Best Together
While each library is powerful on its own, NumPy and Pandas complement each other perfectly. NumPy excels at raw numerical computation, while Pandas provides the structure and tools to work with labeled, real-world datasets. Most machine learning workflows use them in tandem, starting with Pandas for cleaning and organising data, and then leveraging NumPy for high-speed mathematical operations during model preparation.
The Foundation for Machine Learning Success
No matter how advanced an AI model is, it can only perform well with clean, well-structured data. NumPy and Pandas make that possible by turning chaotic raw inputs into reliable, structured datasets ready for analysis and training. In essence, they are the backbone of data preparation, ensuring that the hard work of building ML models begins on solid ground.
Scikit-Learn: The Go-To Library for Classical ML
While deep learning frameworks like TensorFlow and PyTorch often steal the spotlight, many real-world machine learning problems don’t require complex neural networks. Instead, they rely on classical machine learning algorithms such as linear regression, decision trees, clustering, and support vector machines. This is where Scikit-Learn shines as the most popular and versatile library for traditional ML tasks.
What is Scikit-Learn?
Scikit-Learn (often abbreviated as sklearn) is a Python library built on top of NumPy, SciPy, and Matplotlib. It provides a simple, consistent interface for implementing a wide range of machine learning algorithms, making it the go-to tool for data scientists and ML practitioners who want efficiency without unnecessary complexity.
Key Features That Make It Indispensable
Rich collection of algorithms: Includes regression, classification, clustering, dimensionality reduction, and ensemble methods.
Preprocessing tools: Easily handle feature scaling, normalisation, one-hot encoding, and missing data.
Model selection: Offers built-in cross-validation, hyperparameter tuning (GridSearchCV, RandomizedSearchCV), and performance metrics.
Pipelines: Streamline workflows by chaining preprocessing and modeling steps into one repeatable process.
Integration: Works seamlessly with Pandas for data handling and NumPy for numerical computation.
Why It’s the First Choice for Classical ML
Unlike deep learning libraries that require GPU acceleration and complex setups, Scikit-Learn is lightweight and easy to use. It is ideal for:
Prototyping: Quickly testing multiple algorithms with minimal code.
Small to medium datasets: Handling structured/tabular data efficiently.
Education: A favourite among students and beginners due to its clean API and documentation.
Production-ready solutions: Provide reliable and well-tested implementations trusted in the industry.
TensorFlow: Scalable Deep Learning at Its Core
As artificial intelligence continues to expand into industries like healthcare, finance, retail, and autonomous systems, the demand for scalable deep learning solutions has skyrocketed. At the center of this evolution is TensorFlow, one of the most widely used frameworks for building and deploying deep learning models. Originally developed by Google Brain, TensorFlow was designed with scalability, flexibility, and production readiness in mind, making it the go-to tool for both researchers and enterprises.
What is TensorFlow?
TensorFlow is an open-source machine learning framework that provides tools for developing, training, and deploying models at scale. Unlike traditional ML libraries, TensorFlow supports everything from small experimental projects to enterprise-grade AI systems running across multiple GPUs and distributed environments.
Key Features That Make TensorFlow Powerful
Scalability: Runs efficiently on CPUs, GPUs, and TPUs, supporting distributed training for massive datasets.
Flexibility: Offers both low-level APIs for building custom architectures and high-level APIs like Keras for rapid prototyping.
Production readiness: TensorFlow Serving and TensorFlow Lite enable smooth deployment to servers, mobile devices, and edge hardware.
Visualisation with TensorBoard: Provides real-time insights into model training, performance metrics, and debugging.
Community and ecosystem: Backed by Google and supported by a global developer community with extensive documentation and tutorials.
Why TensorFlow Stands Out
While other frameworks like PyTorch have gained popularity for research, TensorFlow’s strength lies in bridging the gap between research and production. Companies can experiment with deep learning models and then deploy them seamlessly at scale, whether that’s powering recommendation engines, detecting fraud, or enabling real-time translation in mobile apps.
The Core of Modern Deep Learning
Deep learning has become the driving force behind today’s most advanced AI systems, and TensorFlow provides the foundation to make these breakthroughs practical and scalable. Whether it’s for academic research, enterprise solutions, or real-time mobile applications, TensorFlow stands as a cornerstone of modern AI development.

PyTorch: Flexibility and Research-Friendly AI Development
When it comes to deep learning frameworks, two names dominate the field: TensorFlow and PyTorch. While TensorFlow often leads in production scalability, PyTorch has earned its reputation as the framework of choice for researchers, innovators, and experimental AI development. Backed by Meta (formerly Facebook) AI, PyTorch combines intuitive design with powerful flexibility, enabling rapid prototyping and cutting-edge research that pushes AI forward.
What is PyTorch?
PyTorch is an open-source machine learning framework designed for building and training deep learning models. Unlike older frameworks that focused heavily on rigid computation graphs, PyTorch introduced a dynamic computation graph (also known as “define-by-run”), which allows developers to modify models on the fly, a feature that has made it particularly attractive to researchers experimenting with new architectures.
Key Features That Make PyTorch Research-Friendly
Dynamic Computation Graphs: Models are built in real-time, making debugging and iteration easier than with static graphs.
Pythonic and Intuitive API: Feels like writing native Python code, which lowers the learning curve.
Integration with NumPy: Enables seamless switching between tensors and NumPy arrays for pre-processing and numerical operations.
Strong Community Support: Widely adopted in academia, with research papers, tutorials, and pre-trained models readily available.
TorchScript: Bridges the gap between research and production by allowing PyTorch models to be optimised and deployed efficiently.
Why Researchers Prefer PyTorch
The flexibility of PyTorch means researchers can test bold ideas quickly without being constrained by rigid frameworks. For example:
Developing custom neural network layers with minimal overhead.
Prototyping reinforcement learning agents that require highly adaptive models.
Experimenting with novel architectures in computer vision and natural language processing.
This freedom to experiment is why PyTorch dominates in academic papers, conferences, and AI research labs.
PyTorch’s Role in AI Development
PyTorch may have started as the “researcher’s framework,” but it has grown into a balanced ecosystem supporting both experimental development and real-world deployment. Its ease of use, flexibility, and strong academic backing make it the go-to choice for AI innovation, and its expanding production capabilities ensure it remains a serious player in enterprise AI as well.
Keras: Simplifying Neural Network Building
Building deep learning models used to be a task reserved for experts who could navigate the complexities of low-level frameworks. Today, thanks to Keras, even beginners can design, train, and deploy powerful neural networks with just a few lines of code. Originally developed as a high-level API for deep learning, Keras has become a cornerstone of the AI ecosystem by making neural network development simple, intuitive, and accessible.
What is Keras?
Keras is an open-source high-level neural networks API, written in Python and capable of running on top of TensorFlow, Theano, and Microsoft Cognitive Toolkit (CNTK) in its early days. Since 2017, it has been tightly integrated into TensorFlow as the official high-level API, making model building both faster and more user-friendly.
Its design principle is clear: “Deep learning for humans.”
Key Features That Make Keras Simple Yet Powerful
User-Friendly API: Provides clean, modular building blocks like layers, optimisers, and loss functions.
Rapid Prototyping: Build and test neural networks in minutes instead of hours.
Flexibility with TensorFlow: Supports both simple models via the Sequential API and complex architectures via the Functional API.
Pre-trained Models: Offers easy access to state-of-the-art architectures (e.g., ResNet, Inception, MobileNet) for transfer learning.
Cross-Platform Deployment: Models can be deployed on mobile (TensorFlow Lite), browsers (TensorFlow.js), and servers.
Why Developers and Beginners Love Keras
Keras abstracts away the complexity of tensor operations and graph construction, letting developers focus on the idea rather than the implementation details. For example:
A student can quickly learn and build their first image classifier.
A researcher can prototype a new neural network design before scaling it in TensorFlow.
A company can accelerate development cycles by reducing the time between concept and deployment.
Keras in the AI Ecosystem
While TensorFlow and PyTorch provide the raw power and flexibility for deep learning, Keras makes that power accessible. It bridges the gap between complex neural network theory and real-world application, democratising AI for a broader audience.
NLTK and SpaCy: Natural Language Processing Made Easy
Language is one of the most complex forms of human expression, and teaching machines to understand it is at the heart of Natural Language Processing (NLP). From chatbots and sentiment analysis to machine translation and search engines, NLP powers many of the AI-driven applications we use daily. Two libraries stand out as essential tools for developers in this space: NLTK (Natural Language Toolkit) and SpaCy. Together, they make working with human language not only possible but also efficient and intuitive.
NLTK: The Foundation of NLP Learning
NLTK, one of the oldest and most comprehensive NLP libraries, is widely used in education and research. It comes with a rich collection of linguistic resources, including tokenizers, stemmers, lemmatizers, and even corpora like WordNet.
Key strengths of NLTK:
Educational focus: Great for learning and teaching NLP concepts.
Wide range of tools: Supports tokenisation, stemming, POS tagging, parsing, and semantic reasoning.
Rich linguistic datasets: Includes corpora and lexical resources that are ideal for experimentation.
Example use case: A student building a sentiment analysis project can use NLTK to break text into tokens, remove stop words, and analyse word frequencies.
SpaCy: NLP for the Real World
While NLTK is great for learning, SpaCy is built for production-ready NLP. It is optimised for speed, scalability, and integration into larger AI systems. SpaCy comes with pre-trained statistical models and word vectors, making it possible to build robust NLP pipelines quickly.
Key strengths of SpaCy:
High performance: Processes text faster than most other libraries.
Industrial focus: Designed for building real-world applications like chatbots, search engines, and information extraction tools.
Modern NLP techniques: Includes named entity recognition (NER), dependency parsing, and support for deep learning integrations.
Seamless integration: Works smoothly with TensorFlow, PyTorch, and Hugging Face Transformers.
Example use case: An enterprise deploying a customer support chatbot can use SpaCy to identify intents, extract named entities, and feed structured information into a response system.
NLP Made Easy
Together, NLTK and SpaCy lower the barriers to working with natural language. They transform complex linguistic tasks into accessible workflows, enabling developers, researchers, and businesses to harness the power of human language in AI.
Whether you’re a student running your first sentiment analysis experiment or a company deploying large-scale NLP solutions, NLTK and SpaCy make natural language processing easier, faster, and more powerful.
OpenCV: Powering Computer Vision Applications
From facial recognition on smartphones to autonomous vehicles identifying objects on the road, computer vision has rapidly transformed the way machines interact with the world. At the center of this revolution lies OpenCV (Open Source Computer Vision Library) one of the most widely used and versatile libraries for image processing and computer vision. With its vast toolkit and ease of integration, OpenCV powers everything from academic research to real-world AI applications.
What is OpenCV?
OpenCV is an open-source computer vision and machine learning library originally developed by Intel in 2000. Today, it has grown into a massive ecosystem supported by a global community. Written in C++ with bindings for Python, Java, and other languages, OpenCV provides thousands of optimised algorithms for image and video analysis, making it a go-to choice for developers across industries.
Key Features That Make OpenCV Essential
Image Processing: Supports operations like filtering, edge detection, thresholding, and morphological transformations.
Object Detection & Recognition: Includes pre-trained models for faces, eyes, pedestrians, and more.
Video Analysis: Enables motion tracking, background subtraction, and real-time video capture.
Machine Learning Integration: Works seamlessly with TensorFlow, PyTorch, and Scikit-learn for building vision-powered AI systems.
Cross-Platform Support: Runs efficiently on desktops, mobile devices, and embedded systems.
Why OpenCV Dominates in Computer Vision
The strength of OpenCV lies in its balance of performance, flexibility, and accessibility. It is lightweight enough for real-time processing on edge devices, yet powerful enough to support advanced research and enterprise solutions. Whether you are detecting license plates, analysing medical scans, or enabling augmented reality applications, OpenCV provides the foundation.
OpenCV: The Backbone of Vision-Powered AI
As computer vision continues to expand into everyday technology, OpenCV remains the core toolkit for developers and researchers. Its speed, wide feature set, and community-driven development ensure that it stays relevant in an era where visual intelligence is becoming indispensable.
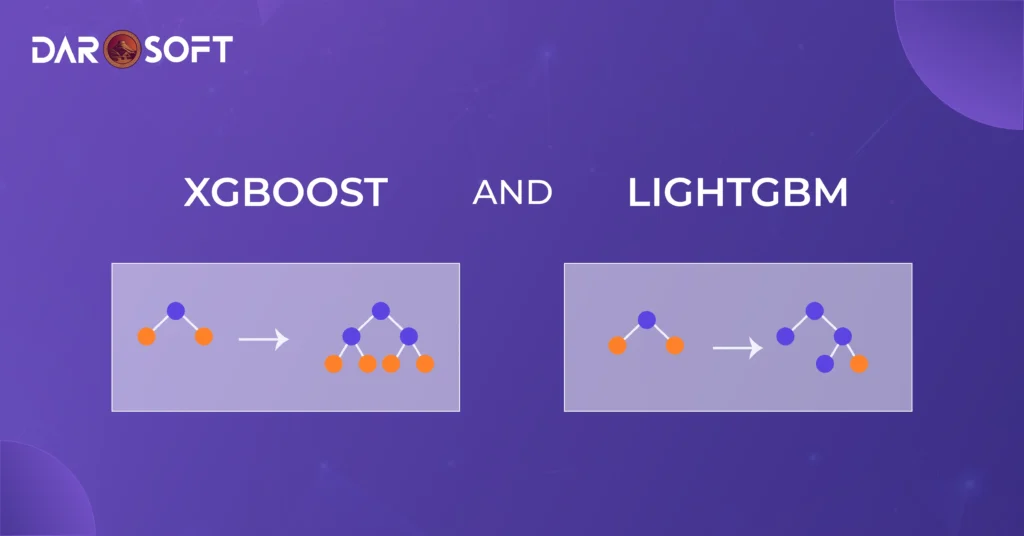
XGBoost and LightGBM: Boosted Models for Speed and Accuracy
When it comes to structured and tabular data, boosted tree algorithms often outperform deep learning models in terms of both accuracy and efficiency. Among these, XGBoost (Extreme Gradient Boosting) and LightGBM (Light Gradient Boosting Machine) have emerged as two of the most powerful libraries, widely used in data science competitions, research, and industry applications. Their combination of speed, accuracy, and scalability makes them the go-to choice for predictive modeling.
Why Gradient Boosting Matters
Gradient boosting is an ensemble learning technique that builds a series of weak learners (usually decision trees), each correcting the errors of its predecessor. Over time, these models combine to form a strong predictor. Compared to simple models, gradient boosting delivers:
Higher accuracy by capturing complex relationships.
Robustness against overfitting when tuned properly.
Strong performance on medium-sized structured datasets.
XGBoost: The Pioneer in Boosted Trees
XGBoost became popular for its efficiency and winning streak in Kaggle competitions.
Key strengths of XGBoost:
Regularization: Prevents overfitting with L1/L2 penalties.
Parallelization: Speeds up training across multiple cores.
Flexibility: Supports regression, classification, ranking, and custom objectives.
Sparsity handling: Efficiently works with missing or sparse data.
Example use case: Predicting loan default risk using tabular financial datasets with thousands of records.
LightGBM: The Next-Gen Alternative
Developed by Microsoft, LightGBM takes boosting to the next level by optimizing for speed and memory efficiency. It uses a novel approach called leaf-wise growth (instead of level-wise like XGBoost), which often leads to better accuracy with fewer iterations.
Key strengths of LightGBM:
High performance: Trains faster than XGBoost, especially on large datasets.
Memory efficiency: Handles large-scale data without heavy memory consumption.
Categorical feature support: Can handle categorical variables directly without one-hot encoding.
Scalability: Works seamlessly on distributed systems and cloud platforms.
Example use case: Real-time click-through rate (CTR) prediction in online advertising systems.
XGBoost vs. LightGBM: Choosing the Right Tool
XGBoost is often more robust on smaller datasets and provides fine-grained control over regularisation.
LightGBM shines on very large datasets and in scenarios where training speed is critical.
Both libraries are widely trusted, so the choice often depends on the dataset size, complexity, and resource availability.
Matplotlib and Seaborn: Visualising Your AI Insights
Data is the foundation of AI and Machine Learning, but raw numbers alone don’t tell a story. To truly understand patterns, trends, and insights, visualisation is key. This is where Matplotlib and Seaborn, two of Python’s most popular visualisation libraries, play a critical role. Together, they transform complex datasets into clear, compelling visuals that help data scientists, engineers, and business stakeholders make better decisions.
Matplotlib: The Foundation of Data Visualisation
Matplotlib is the most fundamental plotting library in Python and forms the basis for many other visualisation tools. It gives developers fine-grained control over every element of a chart, from colors and line styles to labels and axes.
Key strengths of Matplotlib:
Versatility: Supports line charts, bar graphs, scatter plots, histograms, heatmaps, and more.
Customisability: Every aspect of the visualisation can be tweaked for precision.
Integration: Works seamlessly with NumPy, Pandas, and Jupyter Notebooks.
Example use case: Plotting the loss and accuracy curves during neural network training to track performance over time.
Seaborn: Statistical Graphics Made Simple
Built on top of Matplotlib, Seaborn makes it easier to create beautiful, statistically rich visualisations with minimal code. It comes with built-in themes and functions specifically designed for data analysis and exploration.
Key strengths of Seaborn:
High-level API: Simplifies the creation of complex plots like violin plots, pair plots, and heatmaps.
Statistical focus: Integrates statistical analysis directly into visualisations (e.g., regression lines).
Aesthetics: Automatically applies attractive color palettes and styles.
Data-friendly: Works directly with Pandas DataFrames for faster plotting.
Example use case: Creating a correlation heatmap of features in a dataset to quickly spot relationships before training a machine learning model.
Why They Work Better Together
Matplotlib gives complete control but requires more coding.
Seaborn provides simplicity and elegance but relies on Matplotlib in the background.
In practice, data scientists often start with Seaborn for quick exploration and then refine visuals with Matplotlib when they need precision or customisation.
Visualisations in AI and ML Workflows
Matplotlib and Seaborn are indispensable in every stage of an AI/ML pipeline:
Exploratory Data Analysis (EDA): Spotting outliers, distributions, and correlations.
Model Development: Tracking training metrics and comparing algorithms.
Model Communication: Presenting results to stakeholders clearly and engagingly.
Turning Data Into Insights
Numbers alone can overwhelm, but visuals make insights intuitive and actionable. Whether it’s a data scientist analysing training results or a business leader reviewing AI-driven insights, Matplotlib and Seaborn bridge the gap between raw data and human understanding.
Hugging Face Transformers: Pretrained Models for NLP and Beyond
In the past, building state-of-the-art Natural Language Processing (NLP) models required enormous amounts of data, computing power, and expertise. Today, thanks to Hugging Face Transformers, anyone can access cutting-edge models with just a few lines of code. Hugging Face has democratised AI by providing a library of pretrained models that handle complex tasks like translation, text summarisation, question answering, and even applications beyond text, such as vision and speech.
What Are Hugging Face Transformers?
The Transformers library is an open-source collection of pretrained models based on architectures like BERT, GPT, RoBERTa, T5, DistilBERT, and Vision Transformers (ViT). These models leverage the transformer architecture, which relies on self-attention mechanisms to understand context in data, making them exceptionally powerful for sequence-based tasks.
Key Features That Make Transformers Essential
Pretrained Models: Access thousands of models trained on massive datasets, ready for fine-tuning.
Wide Task Coverage: NLP tasks (sentiment analysis, NER, summarisation), computer vision, speech recognition, and multimodal AI.
Ease of Use: Simple, high-level API that allows developers to deploy powerful models in minutes.
Fine-Tuning Support: Models can be easily adapted to domain-specific datasets with minimal effort.
Integration: Works seamlessly with deep learning frameworks like PyTorch and TensorFlow.
Why Hugging Face Changed the AI Landscape
Before Hugging Face, developing NLP models required weeks or months of training on specialised hardware. Now, developers can:
Load a pretrained BERT model for sentiment analysis in a few lines of Python.
Fine-tune GPT or T5 for custom text generation tasks.
Use Vision Transformers (ViT) for image classification.
This shift has dramatically reduced the barrier to entry, enabling startups, researchers, and enterprises to build advanced AI applications quickly and cost-effectively.
Hugging Face and the Future of AI
With its vibrant community, model hub, and open-source ethos, Hugging Face is more than a library. It’s becoming the platform for applied AI development. By making advanced transformers accessible, Hugging Face accelerates innovation across industries while ensuring researchers and practitioners can build on shared progress.

Choosing the Right Library for Your Project
With Python’s vast ecosystem of AI and Machine Learning libraries, the challenge isn’t whether the tools exist. It’s knowing which one to use for your specific project. Each library comes with its strengths, trade-offs, and ideal use cases. The right choice depends on your project goals, resources, and expertise level.
Define Your Objective First
Before picking a library, ask:
Am I working on data preparation, model building, or deployment?
Do I need a quick prototype or a scalable production solution?
Is my project focused on classical ML, deep learning, NLP, computer vision, or visualisation?
Match Libraries to Use Cases
Data Preparation: Choose NumPy and Pandas for efficient handling and cleaning of datasets.
Classical ML: Opt for Scikit-learn for algorithms like regression, clustering, and SVMs.
Deep Learning: Use TensorFlow for scalability and production, or PyTorch for flexibility and research-driven projects.
Simplified Neural Networks: Leverage Keras for a high-level, beginner-friendly approach.
NLP: Turn to NLTK and SpaCy for foundational tasks, or Hugging Face Transformers for cutting-edge pretrained models.
Computer Vision: Adopt OpenCV for image processing and real-time vision applications.
Boosted Models: Apply XGBoost or LightGBM when speed and accuracy are critical for tabular datasets.
Visualisation: Rely on Matplotlib for customisation and Seaborn for quick, beautiful statistical plots.
Consider Your Constraints
Team Expertise: PyTorch might be easier for researchers, while TensorFlow has stronger deployment support.
Performance Needs: XGBoost and LightGBM shine on structured/tabular data, while Transformers dominate in text-heavy use cases.
Scalability: TensorFlow and Hugging Face models integrate better with cloud platforms for large-scale AI.
Learning Curve: If you’re new, start with Pandas, Scikit-learn, and Keras before moving to more complex frameworks.
Don’t Overlook Ecosystem and Community
An active community means more tutorials, prebuilt models, and faster issue resolution. Libraries like Scikit-learn, TensorFlow, PyTorch, and Hugging Face Transformers benefit from vibrant ecosystems, making them safer long-term bets.
Experiment and Iterate
Sometimes the best way to choose is to prototype with multiple libraries. Start small, compare performance, ease of use, and results, then commit to the one that aligns best with your long-term project goals.
Final Thoughts: The Future of Python in AI
Python’s journey from a general-purpose programming language to the backbone of AI and Machine Learning is nothing short of remarkable. Its simplicity, readability, and rich ecosystem of libraries have made it the go-to tool for researchers, developers, and businesses alike. From data preparation with NumPy and Pandas, to classical ML with Scikit-learn, deep learning with TensorFlow and PyTorch, and state-of-the-art NLP with Hugging Face Transformers, Python provides every building block required to bring AI ideas to life.
Looking ahead, Python’s dominance in AI seems set to continue, but not without evolution. With the growing need for faster computation, larger datasets, and more scalable AI systems, Python is increasingly integrating with optimised backend (like CUDA, C++, and Rust) to balance its ease of use with high performance. Meanwhile, community-driven innovations ensure that Python stays at the forefront, bridging the gap between cutting-edge research and practical applications.
As AI continues to expand into areas like generative AI, multimodal systems, real-time decision-making, and ethical AI practices, Python will remain the trusted companion that makes these breakthroughs accessible. Its strength doesn’t lie in being the fastest language, but in being the most adaptable and universally supported, a language where ideas turn into solutions faster than ever before.