- Written by: Hummaid Naseer
- September 2, 2025
- Categories: AI Tools & Frameworks
Machine Learning (ML) is the branch of artificial intelligence that enables computers to learn from data and improve their performance over time without being explicitly programmed for every task. Instead of following rigid, pre-defined rules, ML systems identify patterns, make predictions, and adapt as they process more information.
From Rule-Based Systems to Self-Learning Algorithms
In the early days of computing, systems operated purely on if-then rules; every possible scenario had to be manually coded. While effective for predictable, repetitive tasks, this approach broke down in complex environments where conditions constantly changed. Machine Learning revolutionized this by introducing algorithms that learn from experience, just as humans do. These systems can refine their predictions as they encounter new data, making them more accurate and versatile over time.
Everyday Examples in Action
You’ve probably used machine learning today without even realizing it:
Email filters that separate spam from legitimate messages.
Streaming recommendations from Netflix or Spotify tailored to your tastes.
Voice assistants like Siri or Alexa improve as they learn your speech patterns.
Fraud detection systems that spot unusual banking transactions in real time.
These examples illustrate why ML matters: it turns static software into adaptive, intelligent systems capable of solving problems in dynamic, real-world contexts. From improving customer experiences to enabling smarter decision-making, Machine Learning is shaping industries, economies, and the way we interact with technology.
A Brief History of Machine Learning
Machine Learning didn’t appear overnight. It’s the product of decades of research, evolving alongside mathematics, computer science, and data availability.
Early Statistical Models (1950s–1980s)
The roots of ML lie in statistics and probability theory. In the 1950s, pioneers like Alan Turing and Arthur Samuel experimented with programs that could “learn” from experience—Samuel famously created a checkers-playing program that improved over time. Early models were heavily statistical, relying on linear regression, decision trees, and basic pattern recognition. However, limited computing power and small datasets kept progress slow.
The Rise of Big Data and AI (1990s–2000s)
The explosion of the internet and affordable computing power in the 1990s changed everything. Suddenly, massive datasets were available, and storage became cheaper. This era saw the rise of support vector machines, ensemble methods like random forests, and improved neural networks. Machine Learning started branching away from pure statistics and toward AI, as algorithms could now train on millions of examples.
Breakthroughs That Shaped the Field (2010s–Today)
Three major forces propelled ML into the mainstream:
Deep Learning – Neural networks with many layers (like those used in image and speech recognition) became practical thanks to GPU acceleration.
Big Data Infrastructure – Tools like Hadoop, Spark, and cloud computing allowed ML models to process massive amounts of information quickly.
Accessible AI Frameworks – Libraries such as TensorFlow, PyTorch, and Scikit-learn democratized ML, enabling developers and researchers worldwide to build and deploy intelligent systems.
Now, Machine Learning is a core driver of innovation in industries from healthcare to finance to autonomous vehicles. The field continues to evolve, with research pushing into areas like reinforcement learning, generative AI, and explainable AI.
Core Concepts and Terminology
Understanding machine learning begins with a few foundational concepts that form the language of the field.
Algorithms, Models, Features, and Labels
Algorithm – A set of rules or mathematical steps used to find patterns in data. Examples include decision trees, linear regression, and neural networks.
Model – The end product of training an algorithm on data. The model makes predictions or classifications based on new inputs.
Features – The measurable properties or attributes used as inputs to the model (e.g., age, income, number of purchases).
Labels – The known outcomes or categories that the model is trying to predict (e.g., “spam” or “not spam”).
Think of the algorithm as the recipe, the model as the finished dish, features as the ingredients, and labels as the taste test verdict.
Training vs. Testing Data
Training Data – A dataset used to teach the algorithm, containing both features and labels.
Testing Data – A separate dataset (not used during training) that evaluates how well the model performs on unseen information.
The separation ensures the model learns general patterns rather than memorizing the training set—a mistake known as overfitting.
Supervised, Unsupervised, and Reinforcement Learning
Supervised Learning – The algorithm learns from labeled data, making predictions based on known outcomes. Used in spam detection, fraud detection, and sales forecasting.
Unsupervised Learning – The algorithm works with unlabeled data, discovering hidden structures or groupings (e.g., customer segmentation, topic modeling).
Reinforcement Learning – The algorithm learns by trial and error, receiving feedback in the form of rewards or penalties. Common in robotics, gaming AI, and autonomous systems.
Types of Machine Learning
Machine learning isn’t a one-size-fits-all approach—different learning types suit different problems and data scenarios. Here’s a breakdown:
Supervised Learning – Prediction from Labeled Data
In supervised learning, the algorithm is trained on a dataset that includes both features (inputs) and labels (desired outputs). The goal is to predict the label for new, unseen data.
Common Uses: Spam filtering, credit scoring, and product price prediction.
Example: Predicting house prices based on size, location, and amenities, using historical sales data as the “labels.”
Key Algorithms: Linear regression, decision trees, random forests, support vector machines (SVMs).
Unsupervised Learning – Finding Patterns in Unlabeled Data
In this method, the algorithm works without predefined labels. It looks for natural structures, groupings, or patterns in the data.
Common Uses: Customer segmentation, market basket analysis, anomaly detection.
Example: Grouping customers into segments based on purchasing behavior without knowing their categories beforehand.
Key Algorithms: K-means clustering, hierarchical clustering, principal component analysis (PCA).
Reinforcement Learning – Learning Through Rewards and Penalties
Reinforcement learning (RL) teaches algorithms to make a sequence of decisions. The model interacts with an environment, receiving feedback in the form of rewards (positive outcomes) or penalties (negative outcomes).
Common Uses: Self-driving cars, robotics, game-playing AI (e.g., AlphaGo).
Example: A robot learns to navigate a maze by getting rewarded for reaching the exit and penalized for hitting walls.
Key Elements: Agent, environment, actions, rewards, and policy.
Semi-Supervised Learning – Best of Both Worlds
Semi-supervised learning uses a small amount of labeled data combined with a large amount of unlabeled data. It’s useful when labeling data is costly or time-consuming.
Common Uses: Fraud detection, speech recognition, and medical diagnosis.
Example: A model learns to classify medical images with only a few labeled scans and many unlabeled ones.
Self-Supervised Learning – Labels from the Data Itself
A newer approach, self-supervised learning, creates pseudo-labels from the data so that models can learn without human-annotated labels. This method has been revolutionary in natural language processing (NLP) and computer vision.
Common Uses: Large language models (like GPT), image recognition, and recommendation systems.
Example: Predicting missing words in a sentence to understand language patterns, and later applying that knowledge to translation or summarization.

Key Algorithms and Their Use Cases
Machine learning algorithms vary in complexity and purpose. Each is designed to solve specific types of problems, and understanding them helps in choosing the right approach for your project.
Linear Regression – Predicting Continuous Values
Purpose: Estimates relationships between variables to predict continuous outcomes.
Use Cases: Price forecasting, sales predictions, risk assessment in finance.
Example: Predicting monthly electricity consumption based on weather data.
Decision Trees – Transparent, Rule-Based Decisions
Purpose: Breaks data into branches using simple rules until a decision is made.
Use Cases: Credit scoring, medical diagnosis, churn prediction.
Example: Determining if a customer will default on a loan based on income, debt, and payment history.
Random Forests – Enhanced Accuracy Through Ensembles
Purpose: Combines multiple decision trees to improve prediction accuracy and reduce overfitting.
Use Cases: Fraud detection, recommendation engines, product categorisation.
Example: Classifying e-commerce products into the correct category using text and image data.
Neural Networks & Deep Learning – Complex Pattern Recognition
Purpose: Layers of interconnected “neurons” process information to detect complex, non-linear patterns.
Use Cases: Image classification, speech recognition, and autonomous driving.
Example: Identifying diseases in X-rays or MRIs using convolutional neural networks (CNNs).
Clustering – Grouping Similar Data Without Labels
Purpose: Group data points based on similarity without predefined categories.
Use Cases: Customer segmentation, market basket analysis, anomaly detection.
Example: Grouping shoppers based on buying patterns to design targeted promotions.
Dimensionality Reduction – Simplifying Complex Data
Purpose: Reduces the number of variables while preserving essential patterns.
Use Cases: Data visualisation, noise reduction, speeding up training.
Example: Using PCA to compress image data for faster facial recognition processing.
Natural Language Processing (NLP) Methods – Understanding Human Language
Purpose: Enables machines to process, interpret, and generate human language.
Key Methods: Tokenisation, word embeddings (Word2Vec, GloVe), transformers (BERT, GPT).
Use Cases: Sentiment analysis, chatbots, document summarisation, and machine translation.
Example: Analysing customer reviews to determine brand sentiment trends.
The Machine Learning Workflow
A successful machine learning project follows a systematic process. Skipping steps or rushing through them often leads to inaccurate predictions, biased models, or wasted resources. The following workflow is a proven roadmap from raw data to real-world impact.
Data Collection & Preprocessing – Laying the Foundation
Objective: Gather quality data and prepare it for analysis.
Key Tasks:
Data sourcing: From databases, APIs, sensors, or web scraping.
Cleaning: Removing duplicates, handling missing values, correcting errors.
Feature engineering: Creating meaningful input variables from raw data.
Normalisation/scaling: Ensuring consistent units and ranges.
Example: A retail company collects historical sales data, cleans up incomplete entries, and engineers features like “holiday season” to improve prediction accuracy.
Model Selection & Training – Choosing the Brain
Objective: Pick an algorithm that best suits the problem and train it with historical data.
Key Considerations:
Nature of the task (classification, regression, clustering).
Size and type of dataset.
Performance requirements (speed, accuracy, interpretability).
Training Process: Feed the algorithm with training data so it can “learn” patterns.
Example: A bank selects a random forest model for fraud detection and trains it on past transaction records.
Evaluation & Validation – Checking the Model’s Pulse
Objective: Test how well the model performs on unseen data.
Techniques:
Train/test split or cross-validation to avoid overfitting.
Performance metrics:
Classification: Accuracy, precision, recall, F1-score, ROC-AUC.
Regression: Mean squared error (MSE), R² score.
Example: A healthcare startup validates its disease prediction model using patient data it has never seen before to ensure reliable performance.
Deployment & Monitoring – Bringing the Model to Life
Objective: Integrate the model into production so it can make predictions in real time.
Key Steps:
Deployment: Hosting the model via APIs or embedding it into applications.
Monitoring: Tracking accuracy, performance, and drift over time.
Updating: Retraining the model when data patterns change.
Example: An e-commerce platform deploys its recommendation model to suggest products, then monitors click-through rates to detect performance drops.
The Role of Data in Machine Learning
In machine learning, data isn’t just fuel. It’s the engine, the roadmap, and the terrain all at once. No matter how advanced the algorithm, poor data will lead to poor results. Success depends on how you collect, prepare, and manage the information you feed into your models.
Data Quality and Cleaning – Garbage In, Garbage Out
Why It Matters: Inaccurate or incomplete data leads directly to incorrect predictions.
Common Issues:
Missing values (e.g., blank fields in survey results).
Outliers that skew results (e.g., one customer spending 100× more than others).
Inconsistent formats (e.g., mixing “01/02/2025” and “Feb 1, 2025”).
Best Practices:
Remove duplicates.
Standardise formats and units.
Use imputation techniques to fill missing data responsibly.
Example: A medical diagnosis model trained with inconsistent patient records will misclassify illnesses, potentially causing harm.
Feature Engineering – Turning Raw Data into Gold
Definition: The process of creating and selecting the most relevant variables (features) for your model.
Why It’s Crucial: Good features can make a simple algorithm perform like a complex one.
Techniques:
Transformation: Scaling, normalising, or encoding categorical variables.
Creation: Combining existing features to make new ones (e.g., from “date of birth” to “age”).
Selection: Removing irrelevant or redundant features that add noise.
Example: In predicting property prices, “distance to nearest school” might be engineered from geographic coordinates to improve accuracy.
Dealing with Bias and Imbalance – Fairness and Accuracy
Bias in Data: When certain groups or outcomes are over- or underrepresented.
Example: A hiring model trained mostly on male applicants might favour men over equally qualified women.
Imbalanced Datasets:
It occurs when one class is much more common than others (e.g., 98% “no fraud” vs. 2% “fraud”).
Can cause the model to ignore the rare but important cases.
Solutions:
Oversampling minority classes (e.g., SMOTE).
Under-sampling the majority classes.
Using metrics like precision-recall instead of accuracy.
Ethical Angle: Addressing bias isn’t just about performance. It’s about responsibility and trust.
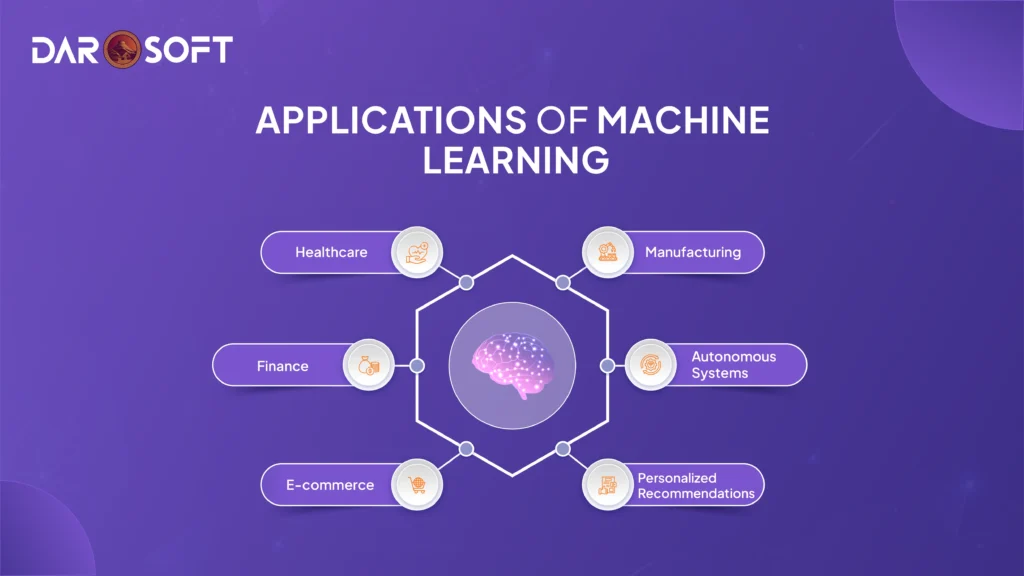
Applications of Machine Learning
Machine learning is no longer confined to research labs. It’s embedded in the technologies and decisions that shape our everyday lives. From life-saving medical diagnoses to personalised shopping experiences, ML is transforming industries at scale.
Healthcare – From Diagnosis to Drug Discovery
Medical Imaging: Algorithms analyse X-rays, MRIs, and CT scans to detect diseases like cancer earlier and with higher accuracy than manual reviews.
Predictive Analytics: ML models predict patient readmission risks, enabling preventive care.
Drug Discovery: Accelerates the search for new treatments by simulating how compounds interact with biological targets.
Example: Google’s DeepMind developed an AI that detects over 50 eye diseases from a single retinal scan.
Finance – Smarter, Faster, Safer Transactions
Fraud Detection: Real-time monitoring of transactions to identify suspicious behaviour patterns.
Credit Scoring: Uses diverse data sources, beyond just credit history, to assess loan eligibility.
Algorithmic Trading: Models execute trades in milliseconds based on market signals.
Example: PayPal’s ML systems analyse billions of transactions daily to stop fraudulent activity before it impacts customers.
E-commerce – Personalisation at Scale
Recommendation Engines: Suggest products based on browsing history, past purchases, and similar customer profiles.
Dynamic Pricing: Adjusts prices in real time based on demand, stock levels, and competitor pricing.
Inventory Optimisation: Predicts demand to prevent overstocking or stock-outs.
Example: Amazon’s “Customers who bought this also bought…” system drives a significant share of its sales.
Manufacturing – Predictive and Adaptive Operations
Predictive Maintenance: Sensors and ML models predict equipment failures before they occur, reducing downtime.
Quality Control: Vision-based systems detect product defects faster and more consistently than human inspectors.
Supply Chain Optimisation: Anticipates delays, adjusts sourcing, and optimises logistics routes.
Example: Siemens uses ML to detect minute deviations in turbine performance, preventing costly breakdowns.
Autonomous Systems – Machines That Learn to Act
Self-Driving Cars: Use ML for object recognition, lane detection, route optimisation, and collision avoidance.
Drones: Learn to navigate environments for delivery, surveillance, or environmental monitoring.
Robotics: Adaptive robots in warehouses adjust to new layouts and products without reprogramming.
Example: Waymo’s autonomous vehicles process sensor data in real time to make split-second driving decisions.
Personalised Recommendations – Beyond Shopping
Entertainment: Netflix, Spotify, and YouTube use ML to suggest content tailored to your taste.
Education: Adaptive learning platforms adjust coursework difficulty based on student performance.
Healthcare: Personalised treatment plans based on genetic data and lifestyle.
Example: Duolingo’s ML algorithms adjust lesson difficulty to keep learners challenged but not overwhelmed.
Challenges and Limitations of Machine Learning
While machine learning offers groundbreaking potential, it’s not without obstacles. Understanding these challenges is essential for building robust, ethical, and trustworthy systems.
Overfitting and Underfitting – The Balance Problem
Overfitting: When a model learns the training data too well, including noise and irrelevant details, it performs poorly on new, unseen data.
Example: A spam filter that memorises exact email phrases rather than learning general spam patterns.
Mitigation: Cross-validation, regularisation, and gathering more diverse training data.
Underfitting: When a model is too simple to capture the underlying patterns in the data, leading to poor accuracy.
Example: Predicting housing prices with only one feature, like square footage, ignoring location or condition.
Mitigation: Using more complex models, better feature engineering, and increasing training time.
Data Privacy and Ethics – The Human Side of AI
Privacy Concerns: ML often requires vast amounts of personal or sensitive data, which raises the risk of data breaches or misuse.
Example: Facial recognition datasets containing images without consent.
Bias and Fairness: Models can perpetuate or amplify societal biases if the training data reflects those biases.
Example: Hiring algorithms favouring male candidates due to biased historical data.
Mitigation: Use anonymisation techniques, ensure diverse and representative datasets, conduct fairness audits, and follow data protection laws like GDPR.
Explainability and Transparency – The Black Box Issue
Black Box Models: Complex models, especially deep learning, can make accurate predictions without providing understandable reasoning.
Example: A neural network predicting loan approval without a clear explanation of the decision.
Importance: Lack of transparency can undermine trust, especially in high-stakes fields like healthcare, law, or finance.
Mitigation: Use interpretable models where possible, apply explainability tools like LIME or SHAP, and document model decisions for accountability.
The Future of Machine Learning
Machine learning is moving beyond specialised research labs and niche applications—it’s becoming an invisible yet powerful layer of our daily lives, shaping industries, economies, and personal experiences. As technology evolves, several trends are set to define its next decade.
AI Integration into Everyday Tools – From Novelty to Necessity
Seamless AI Assistants: From document editors that auto-summarise to email tools that predict your replies, AI will be embedded into productivity apps, communication platforms, and design software.
Industry-Specific Integration:
Healthcare: AI-powered diagnostics integrated directly into patient management systems.
Retail: Dynamic pricing and hyper-personalised recommendations baked into e-commerce platforms.
Impact: Users may not even realise they are “using AI”—it will simply be part of the interface, making decisions and suggestions in real time.
Advances in Generative Models – Creative and Practical Applications
Beyond Text and Images: Generative AI is expanding into video, music, and even scientific simulations, enabling faster drug discovery, custom training simulations, and virtual product prototyping.
Personalised Content at Scale: Tools will generate unique ad campaigns, learning materials, or entertainment tailored to individual preferences.
Ethical Considerations: Deepfakes and misinformation risks will push for stronger AI content verification systems.
The Role of Quantum Computing in ML – Speed and Scale Redefined
Why It Matters: Quantum computing promises exponential leaps in processing power, enabling ML models to train and process data far faster than classical computers.
Potential Breakthroughs:
Solving optimisation problems in seconds that currently take hours or days.
Enabling real-time analysis of massive datasets like global climate models or complex genomic data.
Current Limitations: Still in early research stages, with hardware and error-correction challenges to solve before mainstream adoption.
Conclusion
Businesses that understand how to combine cutting-edge algorithms, high-quality data, and human expertise gain a competitive edge that’s difficult to replicate.
The technology provides the horsepower to process and analyse vast datasets at unprecedented speed. Data ensures those insights are grounded in reality, not just statistical noise. Human judgment brings context, ethical considerations, and the creativity needed to act on those insights effectively.
Organisations that strike this balance will not only automate tasks and reduce costs but also unlock innovation, resilience, and long-term growth. In the end, machine learning is not about replacing humans. It’s about augmenting human capability to make better decisions, faster.