- Written by: Hummaid Naseer
- September 3, 2025
- Categories: AI Tools & Frameworks
Data is the fuel. No matter how advanced the model, its performance ultimately depends on the quality of the information it’s trained on. Clean, accurate, and well-structured data enables algorithms to uncover patterns, make predictions, and generate insights with confidence.
The reverse is equally true: garbage in, garbage out. Poor-quality data riddled with errors, inconsistencies, duplicates, or missing values leads to unreliable results, skewed predictions, and costly mistakes. For businesses, this can mean flawed decision-making, wasted resources, and a loss of trust in AI-driven systems.
In short, the foundation of every successful machine learning project isn’t just a great algorithm; it’s a disciplined approach to collecting, cleaning, and validating data.
What Clean Data Means
Clean data isn’t just about removing typos or fixing missing values; it’s about ensuring that every data point contributes meaningfully to the model’s learning process. High-quality data has three essential traits:
Accuracy – The information must correctly represent the real-world facts it’s meant to describe. A mis-labeled image, a wrong date, or an incorrect transaction amount can mislead an algorithm just as much as a glaring software bug.
Completeness – Missing or partial data can distort the model’s understanding. For example, if half the records in a dataset lack customer age, any age-related insights will be unreliable.
Consistency – Data should follow a uniform format and representation. Inconsistent date formats (e.g., MM/DD/YYYY vs. DD/MM/YYYY) or mixed measurement units (e.g., pounds vs. kilograms) can cause processing errors and produce misleading outputs.
Cleaning also involves removing noise, duplicates, and irrelevant features:
Noise – Random or meaningless data points that add variability without a useful signal.
Duplicates – Repeated entries that overweight certain patterns and skew results.
Irrelevant features – Columns or variables that have no meaningful correlation with the target outcome, which can increase model complexity without improving accuracy.
When data is clean, models train faster, perform better, and generalise more accurately, making the difference between a promising AI initiative and one that fails in production.
How Dirty Data Damages Machine Learning Models
Dirty data isn’t just a nuisance it can actively sabotage a machine learning project, leading to inaccurate predictions, biased decisions, and wasted resources. The main ways it causes damage include:
Increased Error Rates
Inaccurate, incomplete, or inconsistent inputs force models to learn from flawed examples. As a result, predictions deviate from reality, driving up error rates in both training and production environments. For example, a mis labeled cancer diagnosis in a medical dataset can cause the model to incorrectly classify similar cases.
Model Bias and Fairness Issues
Skewed or imbalanced datasets can encode and amplify real-world biases. If historical hiring data reflects gender discrimination, a model trained on it will likely reproduce and even strengthen those patterns. Without careful cleaning and balancing, fairness and ethical compliance become impossible.
Wasted Computing and Storage Resources
Processing irrelevant, duplicate, or noisy data increases computational load without adding value. Training times become longer, storage costs rise, and infrastructure is consumed by meaningless processing. In large-scale AI systems, this inefficiency translates into substantial financial waste.
The Data Cleaning Process
Effective data cleaning is a structured, multi-step approach that transforms raw, messy datasets into high-quality inputs ready for machine learning. The process typically involves:
Data Profiling and Quality Assessment
The first step is understanding the current state of your data. This involves running statistical summaries, checking data distributions, identifying anomalies, and measuring completeness. Profiling tools can reveal issues such as unusually high null values, skewed categories, or inconsistent formats.
Handling Missing Values and Outliers
Missing data can be addressed through strategies like imputation (replacing gaps with statistical estimates, model-based predictions, or domain-specific constants) or removal of incomplete records if they are few and non-critical. Outlier values that deviate significantly from the norm should be carefully analysed to determine whether they represent genuine rare events or erroneous entries that need correction or removal.
Normalisation, Standardisation, and Deduplication
Normalisation scales numerical features to a specific range (e.g., 0 to 1) to ensure no single variable dominates model training.
Standardisation adjusts data so it has a mean of zero and a standard deviation of one, which is critical for algorithms sensitive to feature scales, such as gradient descent–based models.
Deduplication removes repeated records to prevent data redundancy from biasing the model. Duplicate entries can cause overfitting by giving certain patterns disproportionate weight.
Tools and Techniques for Data Cleaning
Data cleaning is most effective when supported by the right tools and integrated into a repeatable workflow. Modern machine learning teams rely on a mix of open-source libraries, automation platforms, and pipeline frameworks to streamline the process.
Python Libraries: Pandas, NumPy, Scikit-learn Preprocessing
Pandas provides powerful functions for data wrangling, handling missing values (fillna, dropna), removing duplicates (drop_duplicates), and transforming data with methods like apply() and map().
NumPy offers fast, array-based operations for numerical data, making it easier to normalize, scale, or reshape datasets before modeling.
Scikit-learn’s preprocessing module includes utilities for scaling (StandardScaler, MinMaxScaler), encoding categorical features (OneHotEncoder, LabelEncoder), and imputing missing values (SimpleImputer, KNNImputer).
Automated Data Cleaning Platforms
Commercial and open-source platforms like OpenRefine, Trifacta Wrangler, DataRobot, Paxata, and Talend Data Preparation help non-technical teams clean and standardise datasets without heavy coding. These tools often include visual interfaces for detecting errors, previewing transformations, and generating cleaning scripts for reproducibility.
Integrating Cleaning Pipelines into ETL Workflows
Data cleaning should not be a one-off task; it must be embedded into ETL (Extract, Transform, Load) or ELT workflows. Tools like Apache Airflow, Luigi, or AWS Glue can orchestrate scheduled cleaning processes.
This ensures that every new batch of incoming data is automatically validated, transformed, and standardised before reaching machine learning models.
Such integration reduces human error, enforces consistent cleaning standards, and allows for real-time monitoring of data quality.
By combining robust coding libraries with automation and pipeline integration, organisations can ensure that clean, reliable data flows continuously into their machine learning systems, reducing manual effort and improving scalability.
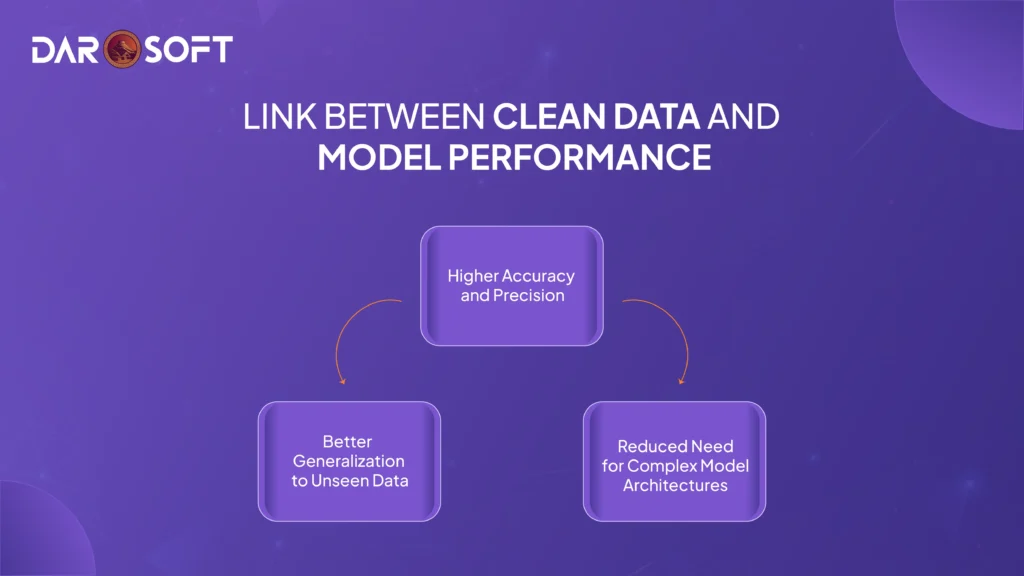
The Link Between Clean Data and Model Performance
Clean, well-structured data doesn’t just make life easier for data scientists; it directly determines how well a machine learning model performs.
Higher Accuracy and Precision
Models trained on accurate and consistent data produce more reliable predictions. Clean data minimises noise and inconsistencies, allowing algorithms to detect genuine patterns rather than random fluctuations. This leads to higher accuracy, precision, recall, and other performance metrics.
Better Generalisation to Unseen Data
The ultimate test of a model is not how well it performs on training data but how it handles real-world, unseen data. Dirty or biased datasets can cause models to overfit the learning quirks of the training set instead of universal patterns. Clean data fosters better generalisation, improving results when the model encounters new scenarios.
Reduced Need for Complex Model Architectures
While advanced algorithms like deep neural networks can sometimes compensate for messy data, they require more computational power, time, and tuning. High-quality data can allow simpler models (e.g., linear regression, decision trees) to perform just as well, saving development time and infrastructure costs.
Case Study: When Clean Data Powers Success
A biotech startup, Viome, has sold over 500,000 AI-powered at-home testing kits that analyse saliva, stool, and blood samples using RNA-based meta transcriptomics. Their key to success lies in rigorous scientific validation and tight integration between data, engineering, and clinical teams. This disciplined approach ensures data accuracy and consistency before feeding into their AI models, yielding reliable recommendations and disease insights. Business Insider
Why It Worked:
Data validation is embedded into every stage, from lab analysis to model deployment.
Clear separation between automated processing and manual validation ensures robust quality control.
Collaboration across research, engineering, and product teams maintains both scientific integrity and scalability.
Case Study: When Dirty Data Broke Demand Forecasting in Retail
A retail chain’s machine learning project aimed to forecast seasonal demand but skipped essential data cleaning steps. The result:
Outdated product IDs misaligned sales records;
Missing weather data skewed seasonal predictions.
Duplicate entries inflated demand forecasts.
The outcome was consistent overstocking, resulting in a ~15% revenue loss from clearance discounts and storage costs. This was all rooted in avoidable data quality issues. Finaloop
What Went Wrong:
The team failed to verify basic data integrity before modeling.
Poor data hygiene led to incorrect input signals, thus poor model outputs.
The financial consequences far exceeded what proper cleaning would have cost.
Best Practices for Maintaining Data Quality at Scale
Continuous Monitoring and Validation
Maintaining data quality is not a one-time task; it requires ongoing vigilance.
Automated Quality Checks: Implement scheduled scripts or pipelines that validate new incoming data against expected ranges, formats, and constraints.
Data Drift Detection: Track distribution changes over time to catch shifts that might degrade model performance.
Real-Time Alerts: Use monitoring tools (e.g., Great Expectations, Monte Carlo) to notify teams instantly when anomalies occur.
Example: A fraud detection system can trigger alerts when transaction patterns deviate significantly from historical norms, prompting immediate review.
Data Governance Frameworks
Clear rules and ownership prevent quality issues from creeping in as datasets grow.
Data Ownership: Assign specific teams or individuals as custodians for each dataset.
Standardised Documentation: Use a data dictionary and schema definitions so that anyone accessing the data understands its meaning, source, and structure.
Compliance & Security: Ensure data handling meets privacy regulations like GDPR, HIPAA, or CCPA, including retention and access policies.
Tip: Tools like Collibra, Alation, or open-source data catalogs can enforce governance at scale.
Cross-Team Collaboration Between Engineers, Analysts, and Domain Experts
Technical expertise alone is not enough; context is equally important.
Joint Data Reviews: Bring together engineers (who know system pipelines), analysts (who know usage patterns), and domain experts (who understand the business meaning).
Feedback Loops: Create structured channels for reporting and resolving data issues quickly.
Shared Metrics: Define what “quality” means in measurable terms accuracy rates, freshness, completeness, and track them across teams.
Example: In healthcare ML projects, clinicians can help identify mislabeled diagnoses that a data engineer might miss.
Data Quality as a Competitive Edge in AI
In the race to build smarter, faster, and more reliable AI systems, clean data isn’t just a technical requirement; it’s a strategic advantage. Organisations that treat data hygiene as a first-class priority consistently produce models that perform better, adapt faster, and inspire more trust from stakeholders.
Turning Clean Data into Better Decisions
When data is accurate, complete, and consistent, machine learning models can extract deeper insights, spot trends earlier, and make predictions with greater confidence. This translates directly into smarter decision-making. Whether it’s predicting customer churn, optimising supply chains, or detecting fraud before it happens.
Why Invest Early in Data Hygiene
Neglecting data quality is like building a skyscraper on shaky ground; problems will emerge, and the cost of fixing them will multiply over time. By investing early in robust data cleaning pipelines, governance frameworks, and monitoring systems, organisations not only safeguard their current AI projects but also create a foundation for scalable, future-proof innovation.
Conclusion
In AI, algorithms may get the spotlight, but data is the stage they perform on. The cleaner and more stable that stage, the better your models and your business will perform.